Ошибка ERR_NGROK_9040. Ngrok закрыл доступ для всех российских IP-адресов
Пользователи массово столкнулись с проблемами в работе ngrok в России — при попытке запустить туннель отображается ошибка: "We do not allow agents to connect to ngrok from your IP address". Это связано с санкциями, которые запрещают предоставление сервиса пользователям из России.
Синхронизация образов в свой Docker Registry
Есть такой инструмент – skopeo, в числе прочего он умеет перепушивать образы из одного регистри в другой, что может быть удобно, если периодически возникает проблема с рейт-лимитом на получение образа. Копировать образ в свой регистри можно было бы и вручную, но не всегда удобно, можно забыть про передачу нужной платформу или у того, кому это срочно надо, нет доступа на пуш. Поэтому в данной заметке предлагаю несложный способ как это можно худо-бедно автоматизировать в Gitlab.
Мои базовые настройки macOS
Каждый раз при смене ноутбука устанавливаю одни и те же настройки, от каких-то избавился, а какие-то со мной уже давно, здесь перечислю, чтобы и самому не забывать и может другим помочь.
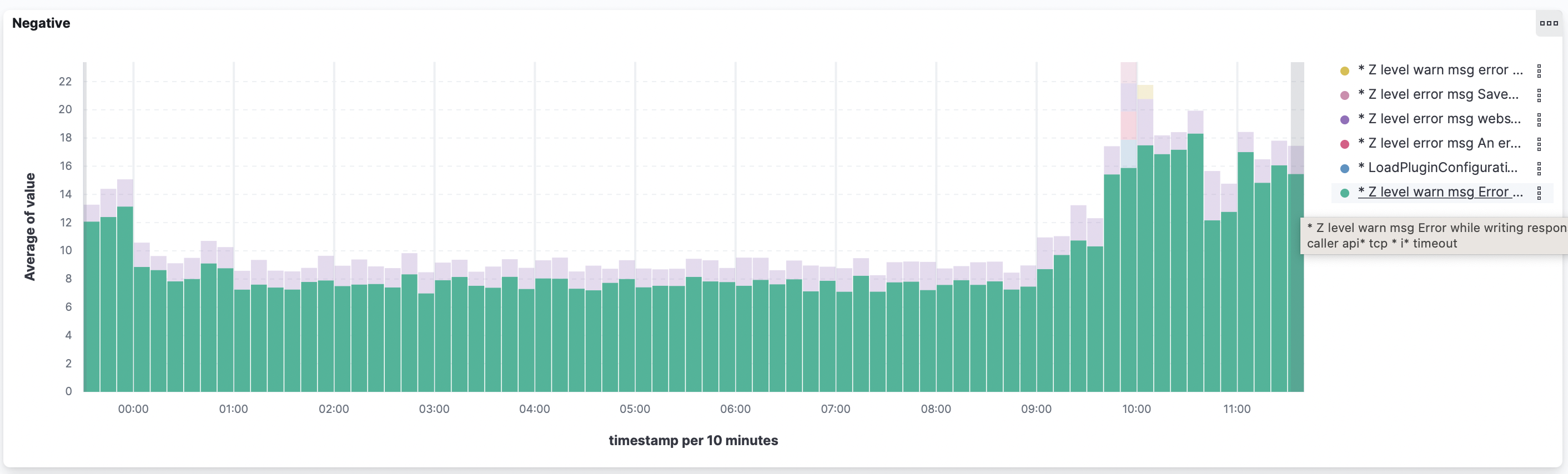
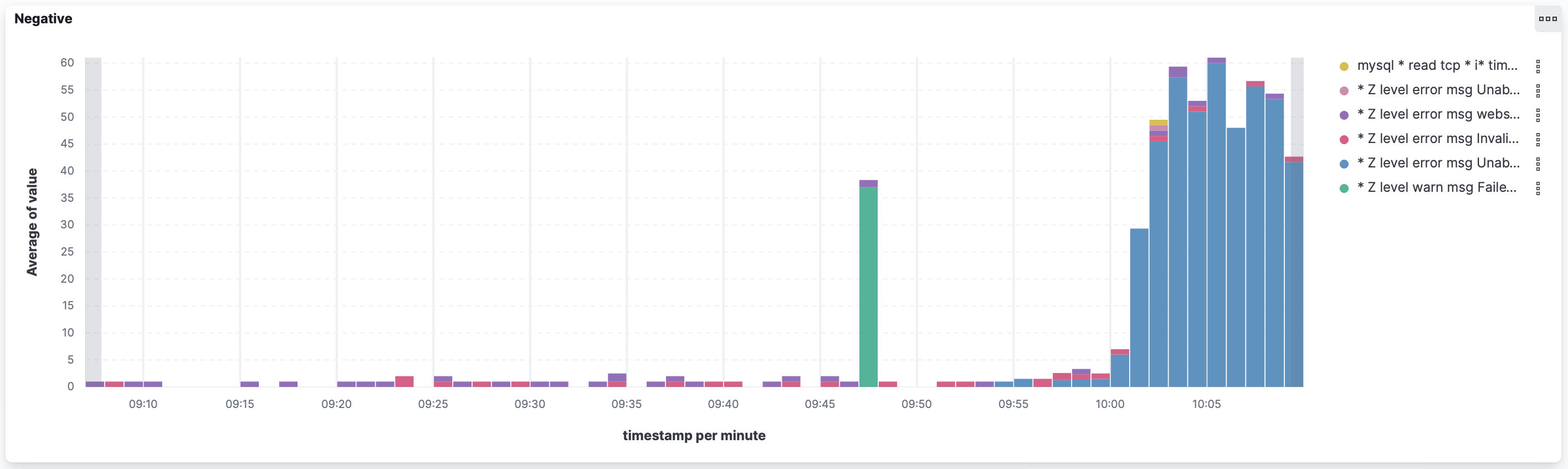
Проверка на дублирование Application в ArgoCD с помощью OPA
Так уж вышло, что в ArgoCD плоская структура для хранения описания приложений - все они живут в одном namespace, а значит должны иметь уникальные имена, чтобы предостеречь себя от разных непонятных ситуаций есть простое решение - проверять, не дублируются ли эти самые имена.
Метрики Qrator (Qrator Exporter)

В очередной раз пришлось настраивать сбор метрик с Qrator, прошлая моя заметка на этот счет жила в виде Issue в репозитории StupidScience/qrator-exporter (в проекте используются deprecated-методы), но там она пропала, поэтому опишу здесь, чтобы уж точно не потерялось.
"Нейронка" для определения ответственного за сервис
Недавно в одном из разговоров я упоминал, что на Prometheus-based стеке смог каждый алерт ассоциировать с командой, которая обслуживает сервис и в случае критических событий эта самая команда меншенится в Slack, чтобы привлечь её внимание. Что ж, показываю как это выглядит в реальности.
Тестирование Helm Chart. Часть 2
В первой части мы проверяли чарты на соответствие нашим ожиданиям по входящим параметрам, хранящимся в values-файлах. В этой части я расскажу, как мы валидируем пользовательские values-файлы к этом чарту, которые правят разработчики, так как проблема остается той же – недопустимый набор входных параметров порождает неприменимые спецификации Kubernetes, что приводит к ошибкам публикации.