Граничные вычисления
Наткнулся на описание интересного термина (на английском звучит как Edge Computing и берет свое начало в 90-х) описывающего архитектуру, при которой данные обрабатываются (анализируются и агрегируются) не в конечной точке своего назначения, а раньше – как можно ближе к источникам данных.
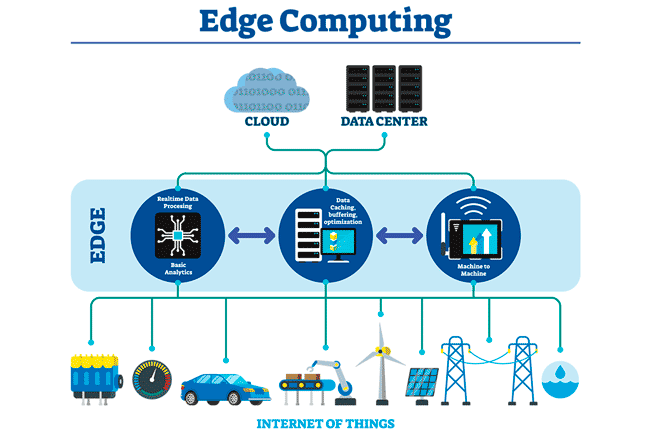
Есть подробная статья, описывающая и проблемы, которые решают граничные вычисления, и примеры задач, которые решаются подобной архитектурой.
Мой интерес к данной архитектуре обусловлен возможностью применения на простых задачах IT-инфраструктуры, ведь архитектура не накладывает ограничений на определенный функционал, теория нам гласит, что функционал может быть ограничен, так как центральная система в принципе много сложнее, но может нам ничего настолько сложного и не надо?
На мой взгляд, оба подхода могут существовать одновременно – на границе мы инициируем события для информирования в режиме реального времени, подключаем к анализу машинное обучение, ищем необходимые паттерны поведения, при этом не отказываемся от централизованного хранения данных, для последующего анализа. Речь, конечно же, о журналировании и телеметрии.
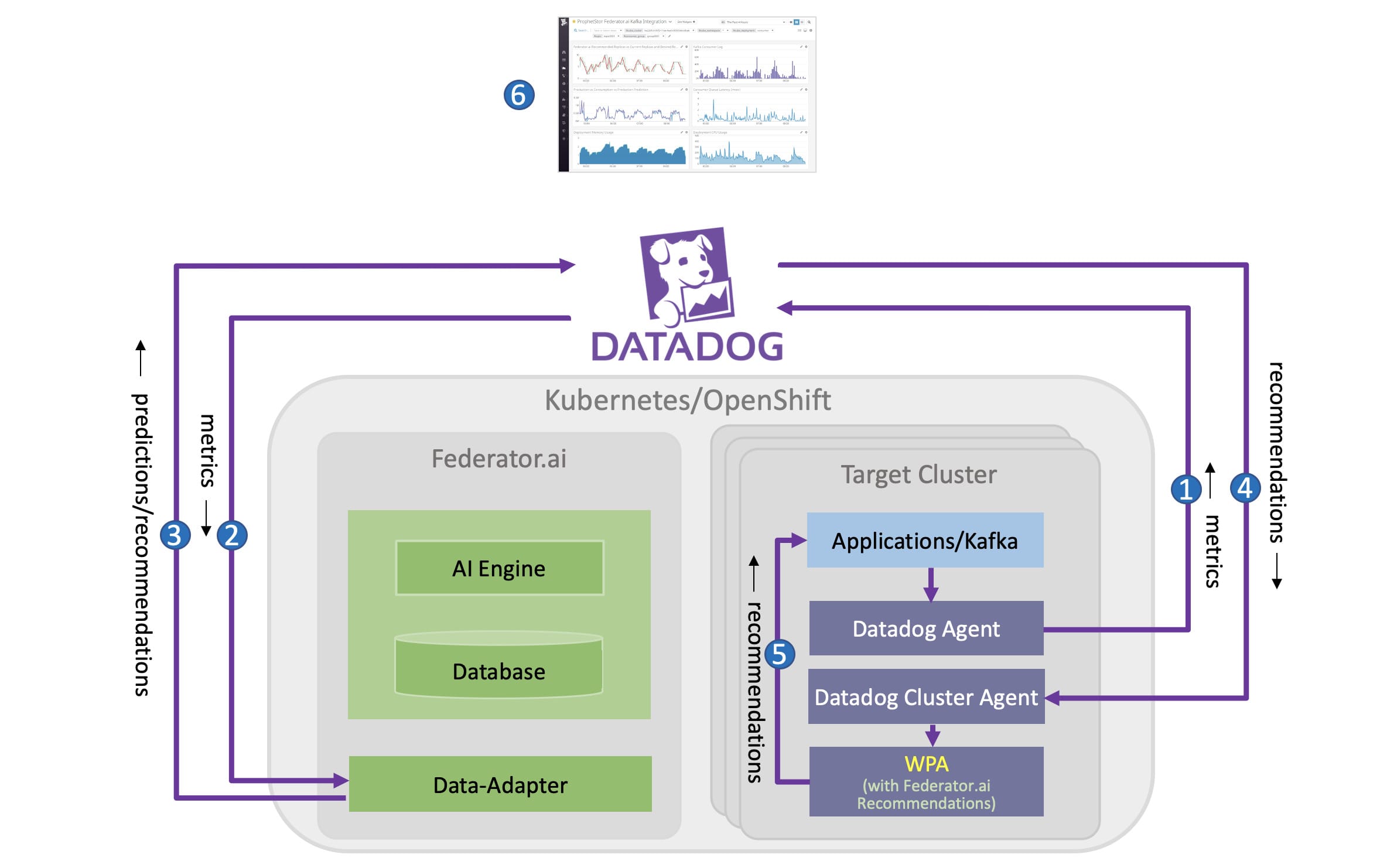
Чаще всего системы для сбора телеметрии и/или журналов представляют собой агенты, которые занимаются сборкой, сжатием и отправкой данных, например, DataDog:
Splunk, помимо облачного решения, представляет self-hosted вариант, в котором схема работы системы может выглядить так:
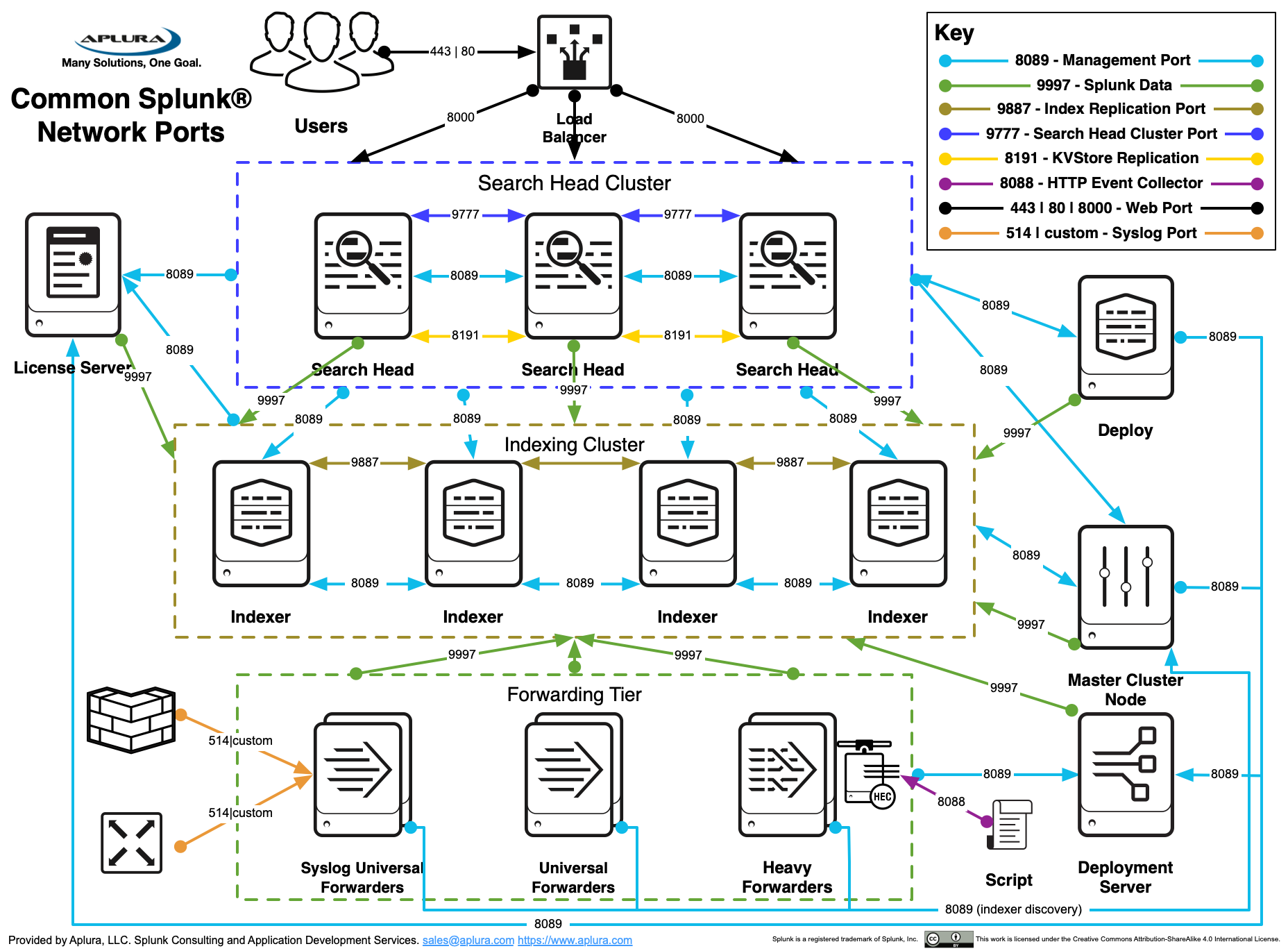
Здесь кластер индексации является отдельным звеном, но, тем не менее, приближен к идеологии централизации, данные, как и в случае DataDog передаются форвардерами и индексируются, а значит их нужно оплачивать/анализировать в полном объеме.
В случае граничных вычислений процесс обработки журналов мог бы выглядеть следующим образом:
- На узле А собираем журналы;
- С узла А данные для анализа передаются на узел Б;
- На узле Б данные агрегируются и анализируются на предмет аномалий (например, большое число неудачных попыток входа), при возникновении аномалии происходит срабатывание триггера для нотификации;
- С узла А события уровня "error" с контексом из событий всех уровней у нефинансовых сервисов отправляются в Kafka;
- С узла А события всех уровней у финансовых сервисов отправляются в Kafka;
Объем собираемых данных растет год от года – это ни для кого не секрет и реализация архитектуры граничных вычислений в области observability сможет минимизировать нагрузку и траты на большие централизованные системы, но не стоит забывать замечание одной из статей – нельзя заниматься обработкой того, о чем ничего не знаешь, а значит для решения подобных задач потребуются либо готовые кейсы под популярные продукты (Nginx, OpenSSH, StatsD), либо это потребует досконального разбора данных для ручного описания всех метрик и аномалий.